
Moving Operations to Simple with Cynefin
This post was originally published on CIO.com on September 19th, 2019.
Background
In 2007, David Snowden and Mary Boone published an article in the Harvard Business Review called A Leader’s Framework for Decision Making. In it, they describe a way of looking at different classes of problems, and how the methods used to solve those problems will be different depending upon in which context you are operating. They called this framework “Cynefin”, which is a Welsh word that describes the often unforeseen factors that influence our decisions.
When learning about this framework, I could not help but think of their descriptions in the context of many problems that I’ve had to solve over the course of my career in Production Operations and Engineering. The authors even describe Cynefin in a context that will look very familiar to those who have been in this same role: “Leaders who understand that the world is often irrational and unpredictable will find the Cynefin framework particularly useful.”
Irrational and unpredictable? How many production outages have I been involved with that appeared irrational and unpredictable? Most of them! I began to think about how Cynefin could be applied in a DevOps context.
Cynefin
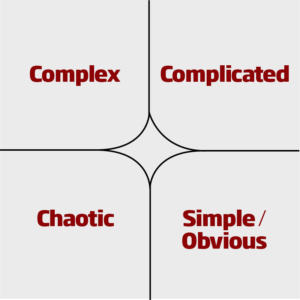
As can be seen in the diagram, Cynefin separates our problem or decision types into 4 distinct quadrants: Simple, Complicated, Complex, and Chaotic. In each of the scenarios, there are different leadership skills that must be applied to successfully navigate the scenario.
Simple/Obvious
The Simple or Obvious domain is one characterized by simple inputs and outputs. A simple input leads to a well defined output. There is no ambiguity. These outputs are often characterized as best practice. If I need to make fries at a fast food restaurant, there is a specific volume of fries and a specific amount of time they must be cooked at a specific temperature. Any deviations from the norm should be minor and should easily be handled by the operator.
Complicated
In the realm of the Complicated, there needs to be some expert knowledge applied to to the problem set, in order to arrive at a decision. The authors called this “good practice” and there needs to be an interpretation of the problem before a decision is made. It is not simply deciding which “best practice” is applied to each situation. An answer is definitely achievable, but it will not necessarily be immediately obvious. “Reaching decisions in the complicated domain can often take a lot of time, and there is always a trade-off between finding the right answer and simply making a decision.”
Complex
According to Snowden and Moore, many problems in organizations can be characterized as complex. These are situations for which there is no clear well defined outcome, and the problem must be probed in order to ascertain the correct path forward. I have seen many production environments that I would consider to be complex. “Complex distributed systems” is a very common phrase in our profession. There are many outages that have happened, because some input to the system had a completely unexpected outcome, and resulted in a major problem.
The Knight Capital disaster is a classic example. No one had predicted that a deviation on one system, would lead to a catastrophic outcome for the company. When dealing in the realm of the Complex, caution is warranted and decisions should be made based on evidence, not simply past experience.
“Most situations and decisions in organizations are complex because some major change…introduces unpredictability and flux. In this domain, we can understand why things happen only in retrospect. Instructive patterns, however, can emerge if the leader conducts experiments that are safe to fail.”
Chaotic
The chaotic is the area of unknown unknowns. As it is described, the only objective in the Chaotic arena, is to remove oneself from that arena, as quickly as possible. Leaders in this area are advised to make a decision, and try and move to another quadrant, any quadrant, from which a definitive path forward can be taken.
In Practice
So, how can we apply Cynefin in a DevOps context? What can we recognize about these four domains that is applicable to our responsibilities of keeping the site up, and keeping developers moving as fast as possible?
“…then sense where stability is present and from where it is absent, and then respond by working to transform the situation from chaos to complexity, where the identification of emerging patterns can both help prevent future crises and discern new opportunities.”
What I came to realize, was that our job in operations is to move problems clockwise around the Cynefin diagram, trying to make most problems faced by developers simple. For example, if I want a new virtual machine in AWS, it is a simple, well defined API call that needs to be made in order for this to happen. All the inputs are well defined, and all the outputs are well understood. Exactly like the bottom right quadrant.
Damon Edwards likes to say that “Operations provides a platform”. As this is the case, then part of our jobs in Operations is to provide a platform, similar to that presented by the AWS API, which enables self-service activity by the development teams, so that tasks they are trying to accomplish are simple and obvious. To ensure it does not require them to apply any expert knowledge to get their work done. I once worked with an engineering team that estimated they spent more than 60% of their time on “plumbing”, or wiring up the virtual hardware necessary for them to accomplish their task. Work that could be provided by a platform developed by Operations. Coaching these teams to a new way of working provided some very quick ROI for that client!
If our goal is to be as close to the Simple quadrant as possible, we can look at some examples where this is not the case, and some ways in which we can do better.
Environments
I have often worked with clients who have made a large effort to build out their production environments where everything is very clean and well defined. That does not mean that the environment is trivial (or obvious) to understand, but they make it possible. They are using Infrastructure as code, they package everything into containers, they do regular deployments, and there is plenty of documentation. I would characterize those environments as Cynefin Complicated. They do require some expert knowledge to understand, but we can reason about them.
When it comes to their staging environments however, these same clients have left it so that everything is a mess. In a misplaced effort to “save money”, the staging environment is where all the corners are cut. Instead of 5 separate web tiers like production, there are 5 web configurations jammed into one host on different ports. Instead of an Oracle RAC database, there is a single Postgres instance that is “close enough”. Of course, as this environment looks nothing like production, it’s basically worthless for testing, and because it’s such a hack of previously isolated things jammed together, we’ve actually moved from Complicated to Complex, and have a much harder time maintaining the environment.
A simpler way to deal with the problem (and save money) is to simply run smaller instances of the production tiers in the staging environments, and use the exact same business logic to build both. If we are running on a c4.4xlarge instance in production, then we can use a c4.large instance in staging (or whatever is appropriate). This way, the environments are basically identical, except for load. This also means that any code intended to manage production can be tested in the staging environment first, and as Gene Kim says: The ability to build representative test environments on demand is one of the strongest indicators of high performing IT teams.
We may not have moved all the way to Simple in this case, but we’re in a much better place then when operating in the Complex.
Deployments
Another example of Cynefin in action can be in our deployment processes. For many years, we have seen deployments as nightmares for Operations teams. Deployments that happen infrequently batch up large amounts of changes just waiting to interact in new and exciting ways under production load.
Often these infrequent releases involve multiple teams, executing a series of steps, all designed to work together over a series of multiple hours, until the deployment is finally complete. If there are any problems, there are complicated rollback procedures, only some of which have been tested. Generally each application will have its **own **deployment procedure depending on its age, coding language, development team, etc. This is definitely in the realm of the Complex, because not only do we need to apply expert knowledge like in Complicated, but because every procedure is a unique snowflake, i.e. we don’t know what effect any one action may have on any other system.
The first step in moving to the complicated would be to try and align all the different deployment schemes around a common pattern or three. In this way, for any one deployment, we only have a limited amount of possibilities to reason about. This can bring us into the area of “good practice”, where we do not need to consider a bunch of anomalous outliers.
If we wish to make the final jump to Simple, we need to create an environment where developers have a self-service platform that is constructed with well defined inputs and outputs. We can use a Chatbot like Hubot, Lita, or Errbot to make the inputs, the interface, uniform for any type of deployment. Regardless of the deployment itself, the interface to the chatbot will make everything appear the same, and return the same well defined output, even as the actual mechanisms for deployment are hidden from the end user. Thankfully, even in this case, the documentation of how the actual deployment is done, is the source code itself, so the mechanisms can be explored and understood as well. In this case, we’ve moved our deployments from Complex to Simple. There is no question: this is a large but worthwhile investment.
Conclusion
Often as leaders, we are asked to make decisions about which is the right path forward. Depending on the context of the situation, there can be different choices made. The Cynefin framework gives us a way to look at these situations, and decide what is the appropriate response.
By applying this same framework to Operations work, we can move toward more self-sufficient, high performing engineering teams. As we create platforms that present engineers with interfaces that are Simple, that are well defined, and don’t require a lot of creativity and expertise to utilize, we allow them to focus on things that do require those skills, like writing code and growing our businesses.
I look forward to exploring the various ways that we can help Operations teams enable development and product to go ever faster in more detail in future columns.