
Deploy on Fridays, or Don't
This post was originally published on Hackernoon on October 24th, 2019.
There seems to be a debate that has gone on for quite some time now on the Twitters about whether or not you should do Friday deploys, and whether there should be Friday moratoriums, etc. There are a lot of accusations being thrown around about fear, testing, time to recover, and the like. To be very clear, I am not a big fan of Friday deploys. That opinion is not based on merely how I feel about deploying on Friday, but also based on the science of it, as well as my learned experience.
With a title like “Deploy on Fridays, or Don’t”, I realize the expected continuation of that statement would be “…I don’t care”. However, nothing could be further from the truth. Let me explain.
My advice to anyone who will listen is, if you’re cautious about your Friday deploys, don’t feel bad, and don’t let anyone make you feel bad.
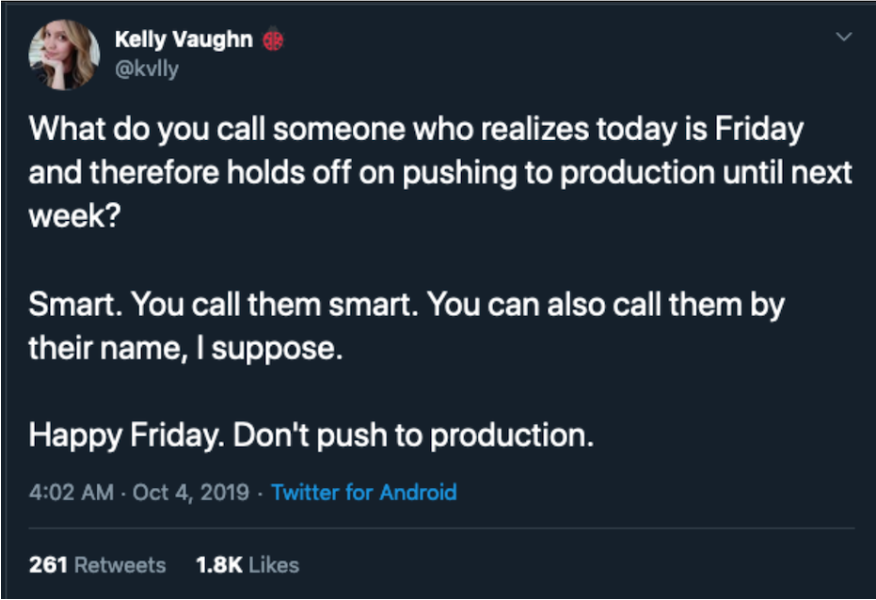
Shaming
It is pretty disconcerting to see a tweet like Kelly’s where the vast majority of the comment thread are attempts to shame anyone for having that opinion. The arguments basically boil down to some variant on
- Deploying shouldn’t be scary
- You should be confident in your deploys
- You lose 20% of your productivity without deploying on Friday
- You just need more tests
Those are all interesting ideas, and they reflect a very interesting type of smug optimism. They are often “backed up” by quoting Accelerate or the State of DevOps report. They eventually arrive at a compromise that you should do the best you can, and keep maturing your deployments until you can deploy anytime you like 365 days with “confidence”. There is also acknowledgement that this can be hard, and having worked with a number of clients and companies over the years, with this I agree.
However, here are most of the problems with the logic:
- Quality Engineering
- Even Elite performers have change failure % > 0
- Mores are not Moratoriums
- All days are not the same
Lastly there is some strange argument that choosing not to deploy on Friday “Shouldn’t be a source of glee and pride”. That one I haven’t figured out yet, because I have always had a lot of glee and pride in being extremely (overly?) protective of the work/life balance of the engineers who either work for me, or with me. I don’t expect that to change.
Quality Engineering
While working at Salesforce, I had the opportunity to learn a lot about quality. This was also the time I when I read Continuous Delivery by Jez Humble and Dave Farley. This was a book that changed my life, and I say that confidently. One of the things I loved about that book was the idea that the more testing that was done, the more confident you could be in the artifact you were deploying. When pitching CI/CD pipeline proposals to executives, they would ask how confident we could be in our artifacts, and I would respond with “How much do you want to spend?”. The more money they were willing to spend, the better testing we could do, and therefore, the more confidence we would have. One of the other things Continuous Delivery taught me was how important it is to have fast feedback. Ultimately, your confidence when deploying to production is going to be some compromise between those two. If you do automated testing for 15 hours, you should obviously have more confidence than if you do so for 30 seconds.
One thing that was not present in the book however, was any notion that you could be 100% confident in what you tested. That is, you could not assure the quality of that artifact tested. Now, Salesforce has a very mature testing pipeline. There were literally hundreds of thousands of tests that were being run more than 5 years ago and yet, they had a quality engineering discipline, but not a quality assurance discipline. Why?
Because one cannot assure quality in software. In manufacturing, if I am making shampoo, I can have quality assurance test for quality. QA takes a statistically representative sample of each bottle of shampoo coming down the line, and test to make sure that the chemical composition of what is being produced is within the tolerances as described by the quality specifications. They statistically assure the company that the quality is consistent.
In software, you cannot do this. You can not take a random sample of code coming through your continuous delivery pipeline, test those lines of code, and then assure that when that code is deployed to production, it will perform at a level consistent with what has been defined.
Therefore it is foolish to lecture people that they should be deploying on Fridays, because they just need to “be confident in their code”, or “write more tests”. How many people dispensing this advice have hundreds of thousands of tests being run on their code? How many people have 100% code coverage in their tests (if this sounds appealing: please don’t do this, the last percentage points will suffer from the laws of diminishing returns)?
What I did not take from Jez and Dave’s book, is that you should fool yourself into thinking that you should be 100% confident in everything you push, just because you have tests. Thankfully, Jez continues to talk (along with Nicole, Gene, and others) about tests in the State of DevOps report.
DORA Report
The DORA Report is often referenced as proof that you should deploy on Fridays, just like any other day. Because it provides data to help classify organizations, including defining how higher vs. lower performing organizations deploy, it’s useful to look at in cases like this. For instance:
- Elite performers - mean change failure rate 7.5%, recovery < 1hr, deploy multiple times a day
- Low performers - mean change failure rate 53%, recovery > 1w, deploy > 1 month
So, assuming that the advice being dispensed is saying “just become an elite performer”, which is in no way a trivial exercise, they still have a mean change failure rate of 7.5%! Does that sound like they will not have any failures during deploys? That’s one way to make Friday afternoon more exciting! I realize the mean recovery time is < 1 hr, but that is also the mean. What does the distribution look like? Is there a cluster at 0%? Is there a cluster at 7.5%? I don’t know. But regardless, there is no guarantee of any deploy being failure free, because even the elite performers have failures.
We also know that change is the leading cause of outages. I’ve seen estimates as high as 75+% of all incidents are at the change boundary. As a friend has said “introducing a change boundary in the 4-6 remaining hours before the whole team is off for 50+ hours seems … like not a high probability play”. But, let’s use the 7.5% change failure rate for elite performers. Do you wear a seatbelt in the car? Yes? Why? What if you had a 7.5% chance of a minor accident? What % chance of a major accident would make you wear a seatbelt? If your argument is that accidents are out of your control, I’d like to introduce you to complex distributed systems…
To put it another way, at Google when you violate your SLO, what is slowed down? Releases. Not more tests, not more monitoring, releases.
The other problem is that it’s not even necessary for you to cause an outage for your weekend to be interrupted. I learned long ago to be very careful about when I did firewall upgrades. Why? Because every firewall upgrade was generally accompanied by days of spurious correlations about whether something was affected by the upgrade. “Dave, I can’t print, didn’t you recently upgrade the firewall?” “Neither the network traffic for your laptop, nor the printer goes through the firewall.” “But couldn’t…” “No”.
Having the capability is necessary
Now choosing not to deploy on Fridays is very different than having the capability to deploy on Fridays. You should have the capability to deploy at any time. Things break, code needs to be shipped. You should absolutely be developing this capability if you do not have it.
I have worked with elite performers. We still chose to be very careful about our Friday deploys.
We also chose to make sure our feature flagging, blue/green, and dark launching capabilities were robust. We had developers deploying their own code whenever they wanted. We deployed multiple services multiple times a day. Every day.
But when Friday afternoon came, if someone was going to push a deploy, they would consider if that was necessary, or if it could wait until Monday. After all, there were other things to do.
Cultural Norms are not Moratoriums
Moratoriums
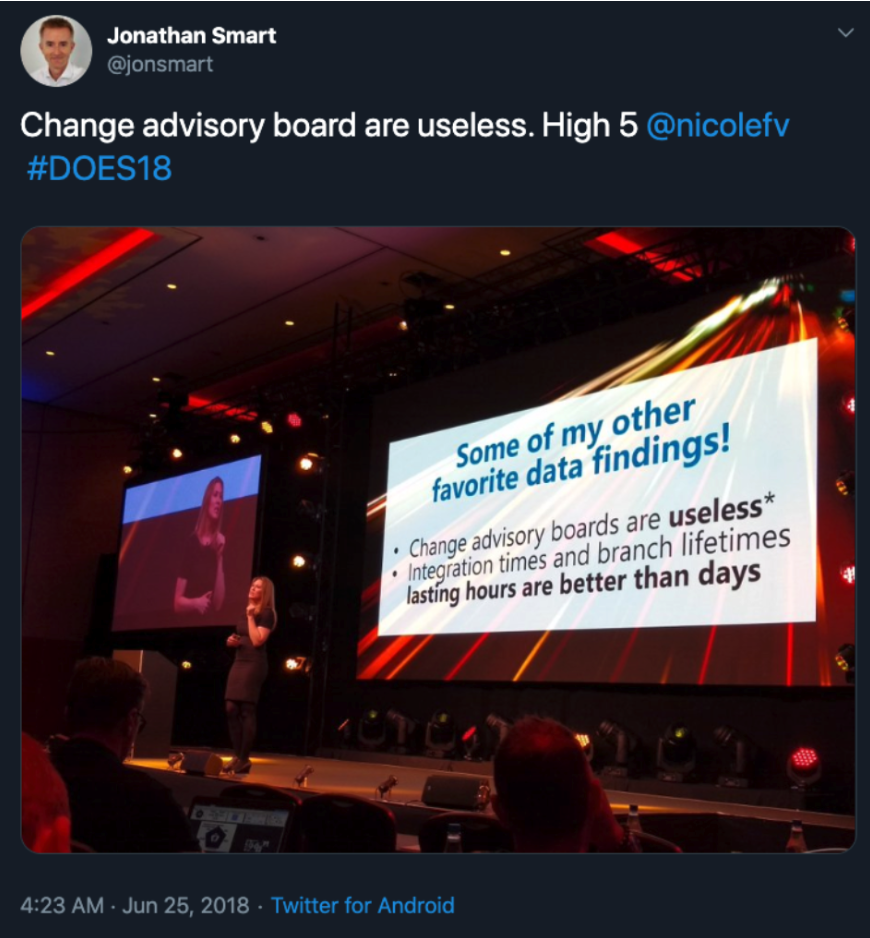
Being choosy about deploying on Friday is not the same as a moratorium. Moratoriums generally require some kind of change advisory board to approve special cases for releasing during the moratorium. Instead, minimizing risk during times where the results of a failure can have outsized impacts is part of the communication and respect we see in DevOps. If the core of DevOps is empathy, then considering the impact our actions can have on others is exactly that - empathetic. Besides, change advisory boards are useless!
Netflix
I was happy to learn that I’m not the only one who has worked at places that were cautious about their Friday deploys when Aaron Blohowiak tweeted about Netflix:
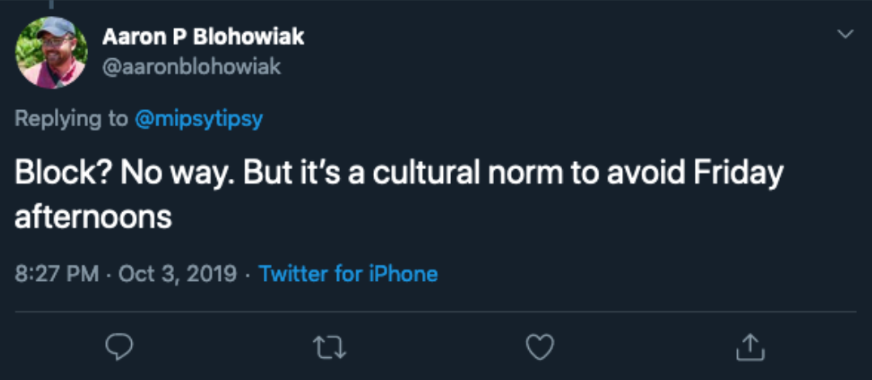
Even the tech giant Netflix has a cultural norm to avoid Friday afternoons. Not a moratorium, but part of the culture of the company.
Another great example from Netflix is the Chaos Monkey. The Chaos Monkey runs during business hours so that people will be more available to respond should something untoward occur. Is that because Netflix doesn’t do enough testing? Or maybe their monitoring is not good enough to run on the weekend? If every hour of every day is exactly the same as every other day, this would make no sense. Instead, they run the Monkey when people are around to address problems, not when they have other commitments.
Complex Distributed Systems
The fact remains that generally we are working on complex distributed systems, and the causes of outages are often elusive. Often when we discover the nature of a problem, it is only obvious in hindsight.
A number of years ago, I was rebuilding a SQL proxy tier at a company. We were automating our proxy builds, and deploying new versions of the software. We used these proxies to keep the short lived nature of our PHP application requests from opening thousands of requests per second to the database. The cost of connection initiation and teardown was not free, so we had an intermediate tier that was designed to take this kind of load much more effectively than the database itself.
I was building the new tier but was not sending any traffic to it because the weekend was coming. After everything was built, things seemed calm. Until about an hour later, when the database started having problems. Connections were randomly timing out. We looked and saw that the database was often hitting max connections and as a result, many requests were not making it through. Ultimately we determined this was because my new tier had opened connections to the DB, even though they were not being used and that had pushed us over the limit when a certain class of traffic appeared. Seems pretty obvious in hindsight and we ultimately determined what happened through monitoring.
But the facts were:
- This was a new tier that had never taken production traffic
- It was in a brand new VLAN that had never seen production
- This was a new version of the software
- The databases had been running fine the entire time this tier was being created
- The new tier had all the latest monitoring on it and showed no signs of problems
- The tier it was replacing also showed no signs of problems
And yet the database was dropping connections, and it was an all hands on deck situation on a Friday afternoon when most people were thinking about their weekend. Thankfully, it was relatively easy to resolve.
Are these types of things common with releasing new software? No, but they happen.
Four Day Work Week
So, if we’re not going to deploy on Friday afternoons, what do we do with that time? Do we just give everyone Friday off? Less shipping means no work? One thing we can do is be protective of our employees through work life balance and reduction of stress.
I have read with great interest about Four day work week experiments. Among the validated results of moving to a four day work week were:
- Boosted productivity
- 24% improvement in work life balance
Being protective of employees is something of which I’ve always been very supportive. Whether it’s booting the person off Hangouts who had a blanket over their head and a hot bowl of soup in their hands, or insisting people take the day off when they’ve been up all night troubleshooting an especially difficult issue after a bad deploy.
I realize most companies are not going to investigate a four day work week, but Friday afternoons can be used for:
- Demos and retrospectives
- Writing documentation
- Mentoring
- 20% time or exploration time
- Working in the staging environment
- Backlog grooming and prioritization
- Team lunches!
At one of the companies I worked for, most of the Ops team would go out for lunch every Friday. That meant lots of Friday morning deploys, and then lots of great collaboration in the afternoon.
If you’re working with a globally distributed team, do you do a Friday afternoon deploy on the west coast of the United States? That’s almost the next day in most parts of Europe. Most Europeans are not excited to be called back to work late in their evening to help figure out why 8% of traffic is getting 500 errors after a Friday afternoon deploy.
Weekends (all days are not the same)
One of my favorite things about working at Salesforce was the number of people who chose to wear Hawaiian shirts on Friday. This is something I’d done on and off over the years ever since the release of Office Space as a way of recognizing the specialness of Friday.
If the argument is that releasing new software is the same regardless of the day, that ignores what people do on weekends. People make plans to go away, they go camping, they go to the opera, they read books in a hammock by the shore. They go to their kids soccer games, they work in the community garden, etc. Do some of those things happen occasionally on a Tuesday night? Sure they do. But the vast majority of weekend travel happens on the weekend and doing activities that can jeopardize that doesn’t show a lot of respect for your coworkers, or your employees’ work/life balance. They need to take this time to rest and recharge.
This is one of the reasons I always liked on-call rotations that rolled over on a Thursday. I always wanted my teams to be able to take a Friday off to get away for a three day weekend. The more downtime in a block, the better.
If the argument is that not shipping on Friday afternoon is going to hurt productivity, remember the old Agile adage “you have to go slow to go fast”. Driving a system at 100% capacity is actually a way to reduce your throughput, not maintain it.
Does this mean that you should never deploy on Friday? Of course not. That also does not mean you shouldn’t consider what you’re deploying. It may seem to make sense when someone says “We scheduled the move from Oracle to Postgres for 4 hours, so if we start at 1 p.m., we should be done in plenty of time.” My answer to that logic is: NOOOOOOOO.
You should be able to, but you don’t have to deploy on Friday afternoon. You should not be shamed for having a culture that respects Friday as being different. It is different.
Deploy on Friday’s or Don’t. The choice is up to you.